
Python课后题

作业 1 Python 语言基础
编写程序,输入本金、年利率和年数、计算复利(结果保留两位小数)
代码
1 | def calculate_compound_interest(principal, rate, years): |
输出结果
1 | PS D:\Documents\StudyData\QFNU\AAA课程\Python\课程\作业1> python -u "d:\Documents\StudyData\QFNU\AAA课程\Python\课程\作业1\2.py" |
编写程序,输入球的半径,计算球的表面积和体积(结果保留两位小数)
代码
1 | import math |
输出结果
1 | PS D:\Documents\StudyData\QFNU\AAA课程\Python\课程\作业1> python -u "d:\Documents\StudyData\QFNU\AAA课程\Python\课程\作业1\3.py" |
编写程序,声明 getValue(b, r, n),根据本金 b,年利率 r 和年数 n 计算最终收益 v,v = b(1+r) n ,然后编写测试代码,提示输入本金、年利率和年数、显示最终收益(保留两位小数)
代码
1 | def getValue(b, r, n): |
运行结果
1 | PS D:\Documents\StudyData\QFNU\AAA课程\Python\课程\作业1> python -u "d:\Documents\StudyData\QFNU\AAA课程\Python\课程\作业1\tempCodeRunnerFile.py" |
编写程序,求解一元二次方程 x² - 10x + 16 = 0
代码
1 | import math |
输出结果
1 | PS D:\Documents\StudyData\QFNU\AAA课程\Python\课程\作业1> python -u "d:\Documents\StudyData\QFNU\AAA课程\Python\课程\作业1\tempCodeRunnerFile.py" |
编写程序,提示输入姓名和出生年份,输出姓名和年龄
代码
1 | # 编写程序,提示输入姓名和出生年份,输出姓名和年龄 |
输出结果
1 | PS D:\Documents\StudyData\QFNU\AAA课程\Python\课程\作业1> python -u "d:\Documents\StudyData\QFNU\AAA课程\Python\课程\作业1\6.py" |
作业 2 程序流程控制
编写程序,格式化输出杨辉三角。杨辉三角即二项式定理的系数表,各元素满足如下条件:第一列及对角线上的元素均为 1;其余每个元素等于它上一行同一列元素与前一列元素之和。
1 | 杨辉三角 |
输入直角三角形的两个直角边,求三角形的周长和面积,以及两个锐角的度数。结果均保留一位小数。其运行效果如图 44 所示。
1 | import math |
编程产生 0~100(包含 0 和 100)的 3 个随机数 a、b 和 c, 要求至少使用两种不同的方法,将 3 个数按从小到大的顺序排序。其运行效果如图 4-5 所示(其中,a、b 和 c 的值随机生成)。
1 | import random |
编程计算有固定工资收入的党员每月所交纳的党费。工资基数 3000 元及以下者,交纳工资基数的 0.5%;工资基数 30005000 元者,交纳工资基数的 1%;工资基数在 5000 10000 元者,交纳工资基数的 1.5%;工资基数超过 10000 元者,交纳工资基数的 2%。运行效果如图 4-6 示。
1 | i = int(input("请输入有固定工资收入的党员的月工资:")) |
编程实现袖珍计算器,要求输入两个操作数和一个操作符(十、一、、/、%),根据操作符输出运算结果。注意“/”和“%”运算符的零除异常问题。其运行效果如图 4-7 所示。
1 | x = float(input("请输入操作数x:")) |
输入三角形的 3 条边 a、b、c, 判断此 3 边是否可以构成三角形。若能,进一步判断三角形的性质,即为等边、等腰、直角或其他三角形。本题的判断准则参见表 4-16。其运行效果如图 4-8 所示。
1 | a = float(input("请输入三角形的边a:")) |
编程实现鸡兔同笼问题。已知在同一个笼子里共有 h 只鸡和兔,鸡和兔的总脚数为 f, 其中 h 和 f 由用户输入,求鸡和兔各有多少只?要求使用两种方法:一是求解方程;二是利用循环进行枚举测试。
1 | h = int(input("请输入总头数:")) |
输入任意实数 x, 计算 e 的近似值,直到最后一项的绝对值小于 10 6 为止
偷个懒,直接用 math 库嘿嘿
1 | import math |
输入任意实数 a(a≥0),用迭代法求 x = √a, 要求计算的相对偏差小于 10 -6 。
1 | def sqrt_iterative(a, tolerance=1e-6): |
我国汉代有位大将,名叫韩信。他每次集合部队,只要求部下先后按 13、15、17 报数,然后再报告一下各队每次报数的余数,他就知道到了多少人。他的这种巧妙算法被人们称为“鬼谷算”,也叫“隔墙算”,或称为“韩信点兵”,外国人还称它为“中国余数定理”。即有一个数,用 3 除余 2,用 5 除余 3,用 7 除余 2,请问 01000 中这样的数有哪些?
1 | print("0~1000中用3除余2,用5除余3,用7除余2的数有:") |
一球从 100 米的高度自由落下,每次落地后反弹回原高度的一半,再落下。·求小球在第 10 次落地时共经过多少米?第 10 次反弹多高?
1 | # 初始高度 |
猴子吃桃问题。猴子第一天摘下若干个桃子,当天吃掉一半多一个;第二天接着吃了剩下的桃子的一半多一个;以后每天都吃了前一天剩下的桃子的一半多一个。到第 8 天发现只剩一个桃子了。请问猴子第一天共摘了多少个桃子?
1 | # 猴子吃桃 |
计算 $S_n = 1+11+111+1111+\ldots+1111$(最后一项是 $n$ 个 $1$)。提示:第 $1$ 项 $T_1 = 1$;第 $2$ 项 $T_2 = T_1 \times 10 + 1$;…;第 $n$ 项 $T_n = T_{n-1} \times 10 + 1$。$n$ 是一个随机产生的 $1$~$10$(包括 $1$ 和 $10$)中的正整数。
1 | import random |
作业 3 常用内置数据类型
编写程序,计算 1+2+3 十十 100 之和。
1 | sum = 0 |
编写程序,计算 10 十 9 十 8 十十 1 之和。
1 | sum = 0 |
编写程序,计算 1 十 3 十 5 十 7 十 99 之和。
1 | sum = 0 |
编写程序,计算 2 十 4 十 6 十 8…十 100 之和。
1 | sum = 0 |
编写程序,使用不同的实现方法输出 2000 一 3000 的所有闰年
1 | for i in range(2000, 3001): |
编写程序,计算 S.= 13+十 5 一 7 十 9 一 11 十…
1 | n = int(input()) |
编写程序,计算 S.= 1 十 1/2 十 1/3 十…
1 | # 求n分之一 |
编写程序,打印九九乘法表。要求输出九九乘法表的各种显示效果(上三角、下三角、矩形块等方式)。
1 | # 打印九九乘法表的矩形块 |
编写程序,输入三角形的 3 条边,先判断是否可以构成三角形,如果可以,则进一步求三角形的周长和面积,否则报错“无法构成三角形!”。其运行效果如图 3-11 所示(结果均保留一位小数)。
1 | a, b, c = ( |
作业 4 序列数据类型
统计单词个数
1 | str = input("请输入字符串:") |
删除 list 重复元素
1 | list = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 1, 2, 3, 4, 5] |
求列表中元素个数,最大值,最小值,元素之和,平均值
1 | s = [9, 7, 8, 3, 2, 1, 55, 6] |
列表内偶数变次方,奇数不变
1 | s = [9, 7, 8, 3, 2, 1, 5, 6] |
将字符串中的每个字符的 ASCII 码存入列表
1 | str = input("请输入字符串:") |
作业 4 附加题
列表元素用特定符号连接
1 | list = ["字符1", "字符2", "字符3", "字符4", "字符5", "字符6"] |
删除列表重复元素,去重元素放到新列表
1 | list = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 1, 2, 3, 4, 5] |
输入多个分数存在列表,去除最高分和最低分,求平均分
1 | lst = list(map(int, input("请输入数字,用空格隔开:").split(" "))) |
空列表的添加,最高最低平均,降序切片,收尾插入,后五替换,奇数删除
1 | # 空列表的添加,最高最低平均,降序切片,收尾插入,后五替换,奇数删除 |
横版竖版输出古诗
1 | # 5.py |
实验 5 输入和输出
解析命令行参数
1 | # https://www.cnblogs.com/techflow/p/13631509.html#/ |
读取文本文件
1 | import argparse |
输入并格式化保存 logs
1 | import argparse |
创建文本文件写入读取
1 | def read_file(): |
csv 文件读取和写入
1 | import pandas as pd |
实验 6 异常处理
异常处理
1 | try: |
实验 7 函数和函数式编程
递归非递归求阶乘
1 | # 递归求阶乘 |
斐波那契数列
1 | # 求斐波那契数列 |
可变参数定义
1 | # 可变参数求任意个数的最小值 |
元组
1 | def analyze_sequence(seq): |
实验 9 附加题
奇偶判断
1 | def isOdd(num): |
阶乘
1 | def factorial(n): |
找最小值
1 | def min_n(a, b, *c): |
列表元组
1 | def analyze_sequence(seq): |
字频
1 | def count_numbers(input_string): |
找数
1 | def My_Search(lst, target): |
斐波那契
1 | def fib(n): |
reduce
1 | from functools import reduce |
正负分离
1 | # 输入一组整数 |
实验 10
pandas 实现 csv 的增删改查
1 | import pandas as pd |

实验 11
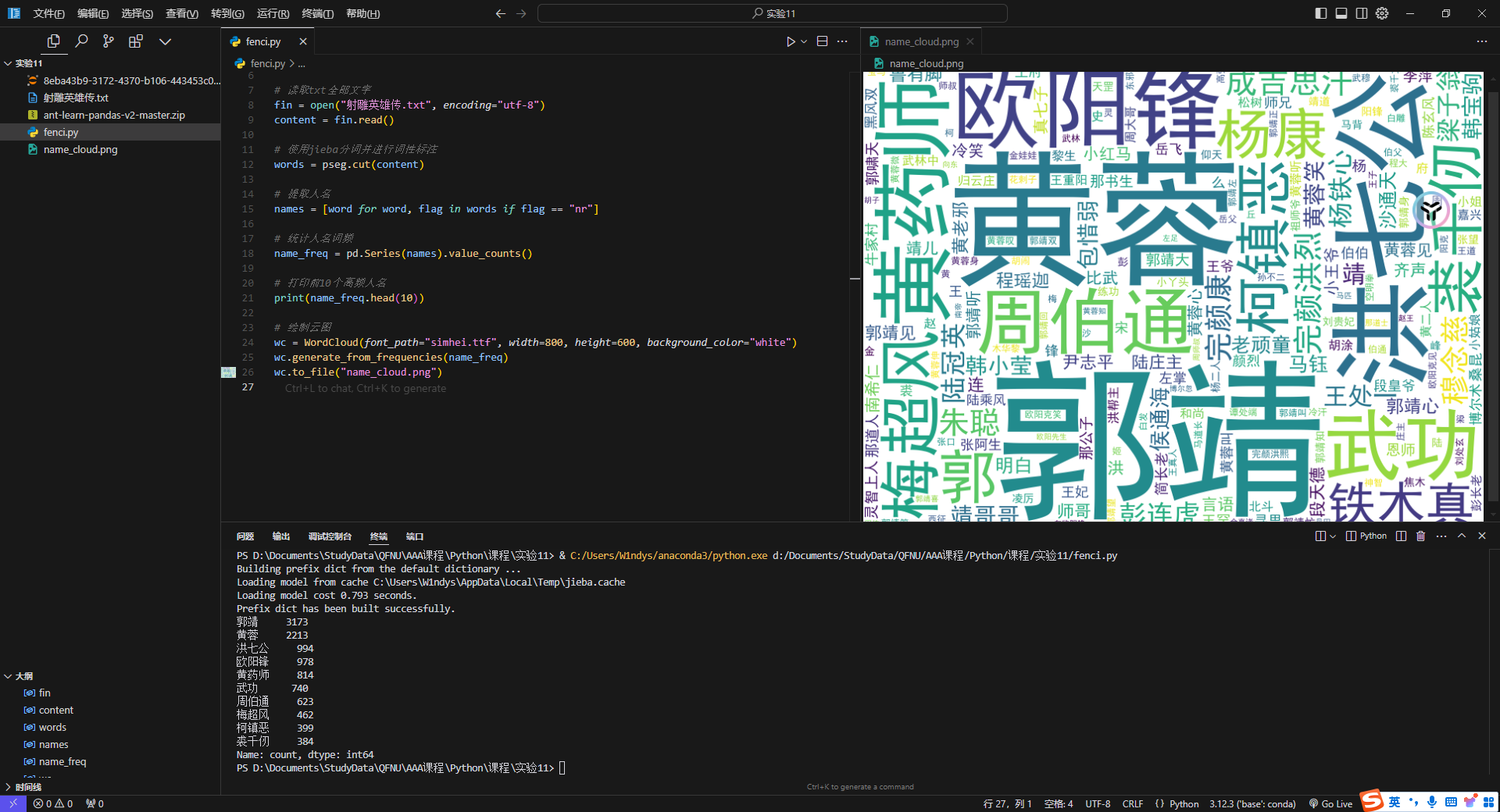
词频统计
1 | import jieba.posseg as pseg |
兴趣推荐
1 | import pandas as pd |
实验 12
练习 1
1 | import numpy as np |
练习 2
1 | import numpy as np |
爬虫实验
地址:爬虫实验
专项知识点-正则表达式
匹配 “abbbbbbbbbc” 中的 “abbbbbbbb”(从贪婪非贪婪角度分析)
正则表达式可以通过贪婪和非贪婪方式进行匹配,分析如下:贪婪模式:使用
.*,匹配尽可能多的字符。1
2
3
4import re
text = "abbbbbbbbbc"
match = re.search(r"ab.*c", text)
print(match.group()) # 输出: abbbbbbbbbc非贪婪模式:使用
.*?,尽量匹配少的字符。1
2
3
4import re
text = "abbbbbbbbbc"
match = re.search(r"ab.*?c", text)
print(match.group()) # 输出: abbbbbbbb
在贪婪模式下,
.*会尽量匹配多的字符,所以结果是abbbbbbbbbc。而非贪婪模式下,.*?会尽量匹配少的字符,所以结果是abbbbbbbb。匹配以字母 “c” 开头的单词
对于这个题目,正则表达式可以通过\bc\w*\b来匹配以字母 “c” 开头的单词,其中\b是单词边界,\w*匹配零个或多个字母、数字或下划线。1
2
3
4import re
content = "The cat sat on the mat and the rat chased the cat"
matches = re.findall(r'\bc\w*\b', content)
print(matches) # 输出: ['cat', 'chased', 'cat']从 HTML 中提取包含
class="active"的列表项中的歌手名和歌曲名
使用re.search查找符合class="active"的li元素,并提取出歌手名和歌曲名。正则表达式可以使用捕获组来提取歌手名和歌曲名。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31import re
html = '''<div id="songs-list">
<h2 class ="title">经典老歌</h2>
<p class="introduction">
经典老歌列表
</p>
<ul id="list" class="list-group">
<li data-view="2">一路上有你</li>
<li data-view="7">
<a href ="/2.mp3" singer="任贤齐">沧海一卢笑 </a>
</li>
<li data-view="4" class="active">
<a href ="/3.mp3" singer="齐秦">往事随风</a>
</li>
<li data-view ="6"><a href="/4.mp3" singer="beyond">光辉岁月 </a></li>
<li data-view="5"><a href="/5.mp3" singer="除慧琳">记事本</a></li>
<li data-view="5">
<a href ="/6.mp3" singer="邓丽君"> 但愿人长久 </a>
</li>
</ul>
</div>'''
# 使用正则表达式匹配 active 类的 <li> 中的歌手和歌曲名
match = re.search(r'<li[^>]*class="active"[^>]*>.*?<a[^>]*singer="([^"]*)"[^>]*>(.*?)</a>', html)
if match:
singer = match.group(1)
song = match.group(2)
print(f"歌手: {singer}, 歌曲: {song}")
else:
print("未找到匹配项")输出:
1
歌手: 齐秦, 歌曲: 往事随风
分析:
这个正则表达式的作用是:r'<li[^>]*class="active"[^>]*>匹配包含class="active"的li元素。.*?<a[^>]*singer="([^"]*)"[^>]*>用来捕获<a>标签中的singer属性(即歌手名)。(.*?)</a>捕获<a>标签中的歌曲名。
数据分析之matplotlib
- 标题: Python课后题
- 作者: W1ndys
- 创建于 : 2024-09-04 08:59:59
- 更新于 : 2025-04-09 18:57:26
- 链接: https://blog.w1ndys.top/posts/9974513c.html
- 版权声明: 版权所有 © W1ndys,禁止转载。
评论